I recently needed to archive a small website before decommissioning it. There are a few distinct reasons you might want an archive of a website:
- To archive the information in case you need it later.
- To archive the look and feel so that you can see how it has progressed.
- To archive the digital artifacts so that you can host them elsewhere as a mirror.
Each of these produces files in a different format, which are useful over different time-periods. In this post, I’ll write a bit about all three, since it’s easiest to archive a website while it is still online.
Saving webpage content to PDF
To write an individual page to a PDF, you can use wkhtmltopdf. On Debian/Ubuntu, this can be installed with:
sudo apt-get install wkhtmltopdf
The only extra setting I use for this is the “Javascript delay”, since some parts of the page will be loaded after the main content.
mkdir -p pdf/
wkhtmltopdf --javascript-delay 1000 https://example.com/ pdf/index.pdf
This produces a PDF file, which you can copy/paste text from, or print.
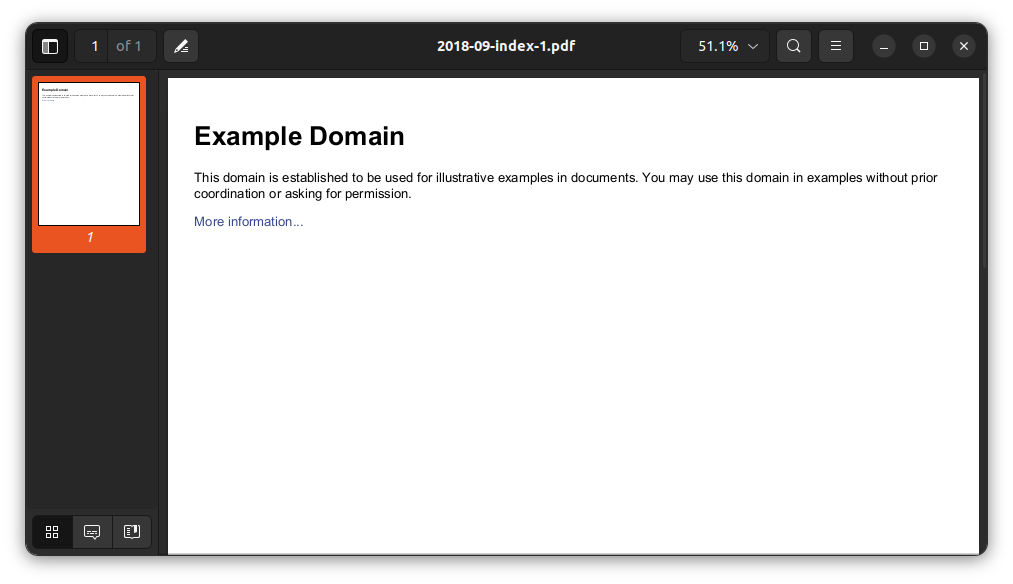
You then simply repeat this for every page which you want to archive.
Saving webpage content to an image
If you are more interested in how the website looked, rather than what it contained, then you can use the same package to write it to an image. I use the jpg format here, because the file sizes are reasonable at higher resolution. I also zoom the page 200% to get higher quality, and selected sizes which are typical of desktop, tablet and mobile screen sizes.
mkdir -p jpg/desktop jpg/mobile jpg/tablet
wkhtmltoimage --zoom 2.0 --javascript-delay 1000 --width 4380 https://example.com/ jpg/desktop/index.jpg
wkhtmltoimage --zoom 2.0 --javascript-delay 1000 --width 2048 https://example.com/ jpg/tablet/index.jpg
wkhtmltoimage --zoom 2.0 --javascript-delay 1000 --width 960 https://example.com/ jpg/mobile/index.jpg
This gives you three images for the page. This example page is quite short, but a larger page produces a very tall image.
The mobile and tablet versions are narrower.

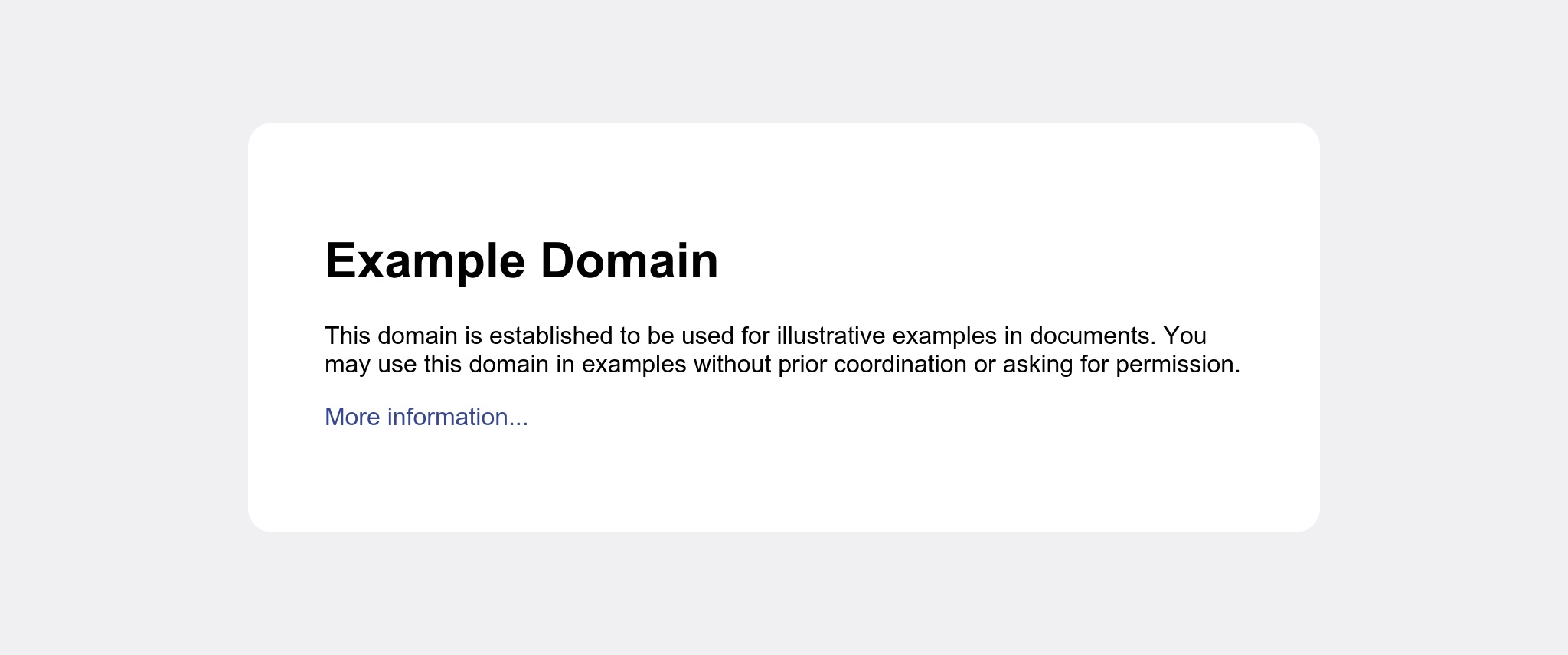
While the desktop version is full-width.

As above, this needs to be repeated for each page which you want to archive.
Mirroring the entire site as HTML
A full mirror of the site is a good short-term archive. Some websites have a lot of embedded external content like maps and external social media widgets, which I would expect to gradually stop working over time as these services change. Still, you might still be able to browse the website on your local computer in 10 or 20 years time, depending on how browsers change.
wget is the go-to tool for mirroring sites, but it has a lot of options!
mkdir -p html/
cd html
wget \
--trust-server-names \
-e robots=off \
--mirror \
--convert-links \
--adjust-extension \
--page-requisites \
--no-parent \
https://example.com
There are quite a few options here, I’ll briefly explain why I used each one:
| Option | Purpose |
|---|---|
--trust-server-names |
Allow the correct filename to be used when a redirect is used. |
-e robots=off |
Disable rate limiting. This is OK to use if you own the site and are sure that mirroring it will not cause capacity issues. |
--mirror |
Short-hand for some options to recursively download the site. |
--convert-links |
Change links on the target site to local ones. |
--adjust-extension |
If you get a page called “foo”, save it as “foo.html”. |
--page-requisites |
Also download CSS and Javascript files referenced on the page |
--no-parent |
Only download sub-pages from the starting page. This is useful if you want to fetch only part of the domain. |
The result can be opened locally in a web browser:
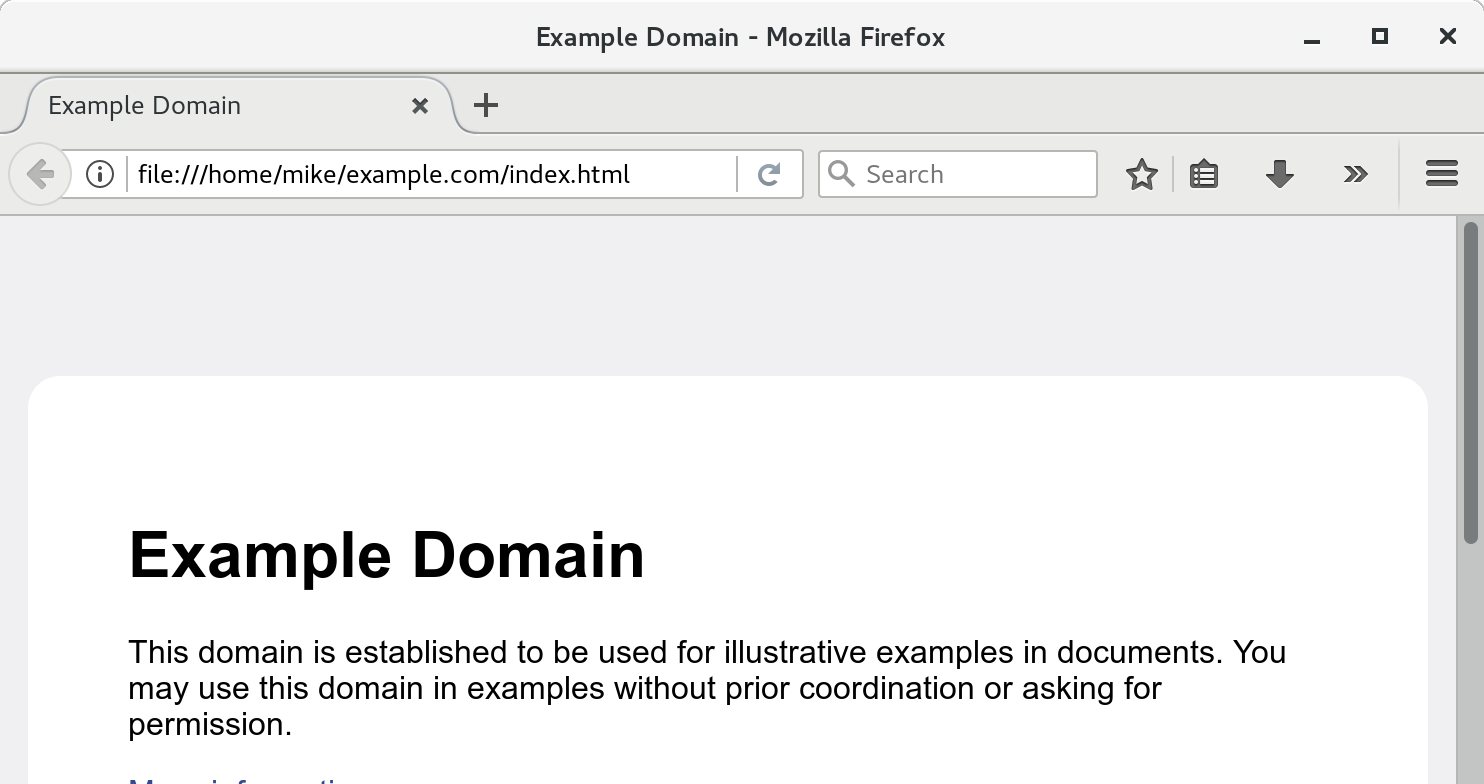
These options worked well for me on a Wordpress site.
Putting it all together
The site I was mirroring was quite small, so I manually assembled a list of pages to mirror, gave each a name, and wrote them in a text file called urls.txt in this format:
https://site.example/ index
https://site.example/foo foo
https://site.example/bar bar
I then ran this script to mirror each URL as an image and PDF, before mirroring the entire site locally in HTML.
#!/bin/bash
set -exu -o pipefail
mkdir -p jpg/desktop jpg/mobile jpg/tablet html/ pdf
while read page_url page_name; do
echo "## $page_url ($page_name)"
# JPEG archive
wkhtmltoimage --zoom 2.0 --javascript-delay 1000 --width 4380 $page_url jpg/desktop/$page_name.jpg
wkhtmltoimage --zoom 2.0 --javascript-delay 1000 --width 2048 $page_url jpg/tablet/$page_name.jpg
wkhtmltoimage --zoom 2.0 --javascript-delay 1000 --width 960 $page_url jpg/mobile/$page_name.jpg
# Printable archive
wkhtmltopdf --javascript-delay 1000 $page_url pdf/$page_name.pdf
done < urls.txt
# Browsable archive
MAIN_PAGE=$(head -n1 urls.txt | cut -d' ' -f1)
mkdir -p html/
(cd html && \
wget --trust-server-names -e robots=off --mirror --convert-links --adjust-extension --page-requisites --no-parent $MAIN_PAGE)
The example.com domain only has an index page, so after running the script against it, it downloads this set of files:
├── archive.sh
├── html
│ └── example.com
│ └── index.html
├── jpg
│ ├── desktop
│ │ └── index.jpg
│ ├── mobile
│ │ └── index.jpg
│ └── tablet
│ └── index.jpg
├── pdf
│ └── index.pdf
└── urls.txt
Happy archiving!