![]()
myki is the public transport ticketing system in Melbourne. If you register your myki, you can view the usage history online. Unfortunately, you are limited to paging through HTML, or downloading a PDF.
This post will show you how to get your myki history into a CSV file on a GNU/Linux computer, so that you can analyse it with your favourite spreadsheet/database program.
Get your data as PDFs
Firstly, you need to register your myki, log in, and export your history. The web interface seemed to give you the right data if you chose blocks of 1 month.
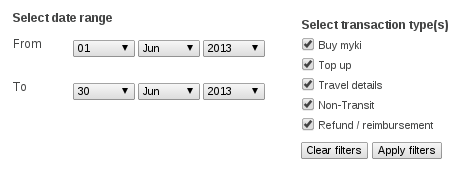
Once you do this, organise these into a folder filled with statements.
You need the pdftotext utility to go on. In debian, this is in the poppler-utils package.
The manual steps below run you through how to extract the data, and at the bottom of the screen there are some scripts I’ve put together to do this automatically.
Manual steps to extract your data
These steps are basically a crash course in "scraping" PDF files.
To convert all of the PDF’s to text, run:
for i in *.pdf; do pdftotext -layout -nopgbrk $i; doneThis preserves the line-based layout. The next step is to filter out the lines which don’t contain data. Each line we’re interested in begins with a date, followed by the word “Touch On”, “Touch Off”, or “Top Up”
18/08/2013 13:41:20 T...We can filter all of the text files using grep, and a regex to match this:
cat *.txt | grep "^[0-3][0-9]/[0-9][0-9]/[0-9][0-9][0-9][0-9] [0-9][0-9]:[0-9][0-9]:[0-9][0-9] *T"The output looks like:
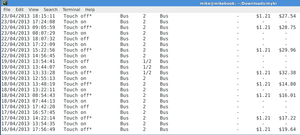
So what are we looking at?
- One row per line
- Fields delimited by multiple spaces
To collapse every double-space into a tab, we use unexpand. Then, to collapse duplicate tabs, we use tr:
cat filtered-data.txt | unexpand -t 2 | tr -s '\t'Finally, some fields need to be quoted, and tabs need to be converted to CSV. The PHP script below will do that step.
Scripts to get your data
myki2csv.sh is a script which performs the above manual steps:
#!/bin/bash
# Convert myki history from PDF to CSV
# (c) Michael Billington < michael.billington@gmail.com >
# MIT Licence
hash pdftotext || exit 1
hash unexpand || exit 1
pdftotext -layout -nopgbrk $1 - | \
grep "^[0-3][0-9]/[0-9][0-9]/[0-9][0-9][0-9][0-9] [0-9][0-9]:[0-9][0-9]:[0-9][0-9] *T" | \
unexpand -t2 | \
tr -s '\t' | \
./tab2csv.php > ${1%.pdf}.csvtab2csv.php is called at the end of the above script, to turn the result into a well-formed CSV file:
#!/usr/bin/env php
<?php
/* Generate well-formed CSV from dodgy tab-delimitted data
(c) Michael Billington < michael.billington@gmail.com >
MIT Licence */
$in = fopen("php://stdin", "r");
$out = fopen("php://stdout", "w");
while($line = fgets($in)) {
$a = explode("\t", $line);
foreach($a as $key => $value) {
$a[$key]=trim($value);
/* Quote out ",", and escape "" */
if(!(strpos($value, "\"") === false &&
strpos($value, ",") === false)) {
$a[$key] = "\"".str_replace("\"", "\"\"", $a[$key])."\"";
}
}
$line = implode(",", $a) . "\r\n";
fwrite($out, $line);
}Invocation
Call script on a single foo.pdf to get foo.csv:
./myki2csv.sh foo.pdfConvert all PDF’s to CSV and then join them:
for i in *.pdf; do ./myki2csv.sh $i; done
tac *.csv > my-myki-data.csvImporting into LibreOffice
The first field must be marked as a DD/MM/YYYY date, and the “zones” need to be marked as text (so that “1/2” isn’t treated as a fraction!)
These are my import settings:
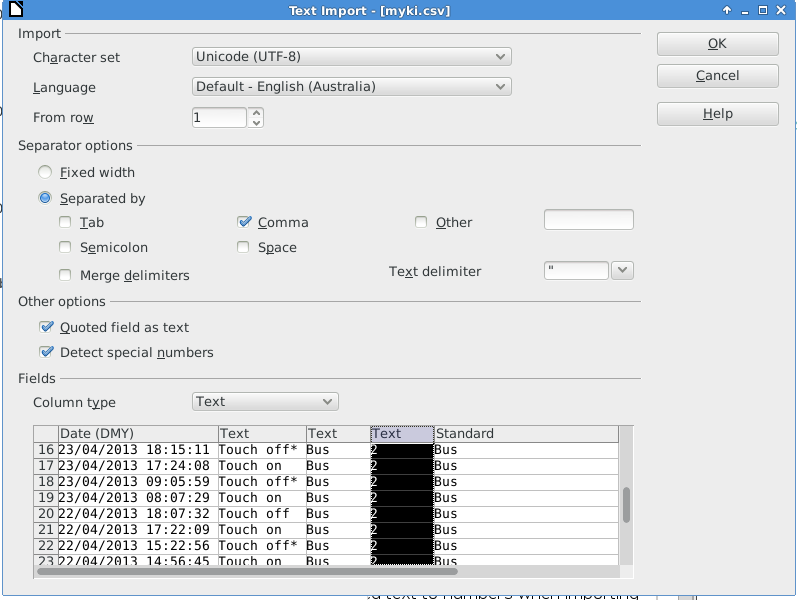
Happy data analysis!
Update 2013-09-18: The -nopgbrk option was added to the above instructions, to prevent page break characters causing grep to skip one valid line per page
Update 2014-05-04: The code for the above, as well as this follow-up post are now available on github.