I’ve had a PHP wikitext parser as a dependency of some of my projects since 2012. It has always been a minor performance bottleneck, and I recently decided to do something about it.
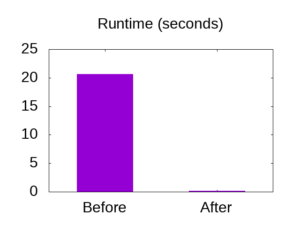
I prepared an update to the code over the course of a month, and achieved a speedup of 142 times over the original code.
A lot of the information that I could find online about PHP performance was very outdated, so I decided to write a bit about what I’ve learned. This post walks through the process I used, and the things which were were slowing down my code.
This is a long read — I’ve included examples which show slow code, and what I replaced them with. If you’re a serious PHP programmer, then read on!
Lesson 1: Know when to optimize
Conventional wisdom seems to dictate that making your code faster is a waste of developer time.
I think it makes you a better programmer to occasionally optimize something in a language that you normally work with. Having a well-calibrated intuition about how your code will run is part of becoming proficient in a language, and you will tend to create fewer performance problems if you’ve got that intuition.
But you do need to be selective about it. This code has survived in the wild for over five years, and I think I will still be using it in another five. This code is also a good candidate because it does not access external resources, so there is only one component to examine.
Lesson 2: Write tests
In the spirit of MakeItWorkMakeItRightMakeItFast, I started by checking my test suite so that I could refactor the code with confidence.
In my case, I haven’t got good unit tests, but I have input files that I can feed through the parser to compare with known-good HTML output, which serves the same purpose:
php example.php > out.txt
diff good.txt out.txt
I ran this after every change to the code, so that I could be sure that the changes were not affecting the output.
Lesson 3: Profile your code & Question your assumptions
Code profiling allows you see how each part of your program is contributing to its overall run-time. This helps you to target your optimization efforts.
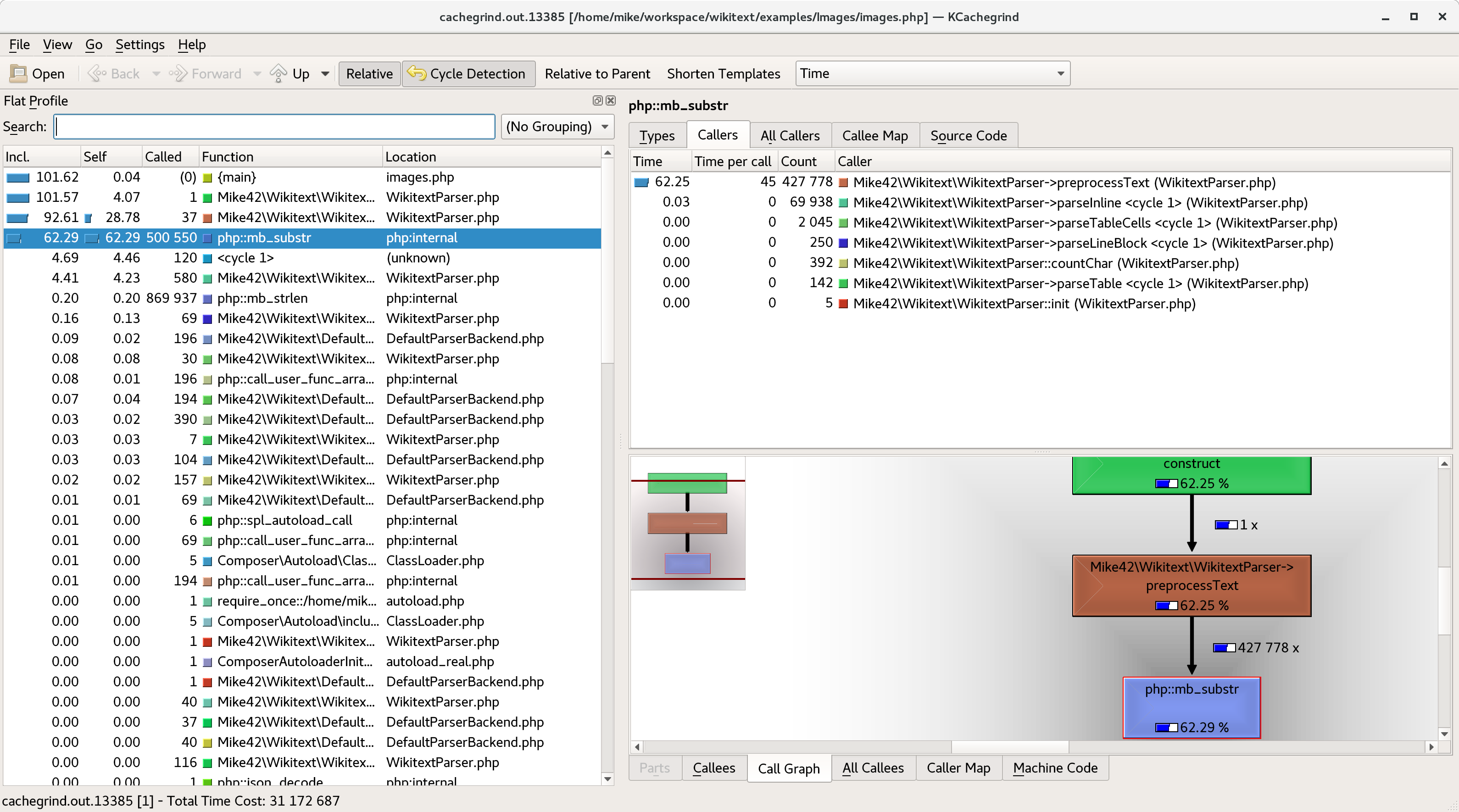
The two main debuggers for PHP are Zend and Xdebug, which can both profile your code. I have xdebug installed, which is the free debugger, and I use the Eclipse IDE, which is the free IDE. Unfortunately, the built-in profiling tool in Eclipse seems to only support the Zend debugger, so I have to profile my scripts on the command-line.
The best sources of information for this are:
On Debian or Ubuntu, xdebug is installed via apt-get:
sudo apt-get install php-cli php-xdebug
On Fedora, the package is called php-pecl-xdebug, and is installed as:
sudo dnf install php-pecl-xdebug
Next, I executed a slow-running example script with profiling enabled:
php -dxdebug.profiler_enable=1 -dxdebug.profiler_output_dir=. example.php
This produces a profile file, which you can use any valgrind-compatible tools to inspect. I used kcachegrind
sudo apt-get install kcachegrind
And for fedora:
sudo dnf install kcachegrind
You can locate and open the profile on the command-line like so:
ls
kcachegrind cachegrind.out.13385
Before profiling, I had guessed that the best way to speed up the code would be to reduce the amount of string concatenation. I have lots of tight loops which append characters one-at-a-time:
$buffer .= "$c"
Xdebug showed me that my guess was wrong, and I would have wasted a lot of time if I tried to remove string concatenation.
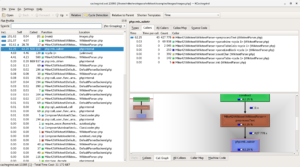
Instead, it was clear that I was
- Calculating the same thing hundreds of times over.
- Doing it inefficiently.
Lesson 4: Avoid multibyte string functions
I had used functions from the mbstring extension (mb_strlen, mb_substr) to replace strlen and substr throughout my code. This is the simplest way to add UTF-8 support when iterating strings, is commonly suggested, and is a bad idea.
What people do
If you have an ASCII string in PHP and want to iterate over each byte, the idiomatic way to do it is with a for loop which indexes into the string, something like this:
<?php
// Make a test string
$testString = str_repeat('a', 60000);
// Loop through test string
$len = strlen($testString);
for($i = 0; $i < $len; $i++) {
$c = substr($testString, $i, 1);
// Do work on $c
// ...
}
I’ve used substr here so that I can show that it has the same usage as mb_substr, which generally operates on UTF-8 characters. The idiomatic PHP for iterating over a multi-byte string one character at a time would be:
<?php
// Make a test string
$testString = str_repeat('a', 60000);
// Loop through test string
$len = mb_strlen($testString);
for($i = 0; $i < $len; $i++) {
$c = mb_substr($testString, $i, 1);
// Do work on $c
// ...
}
Since mb_substr needs to parse UTF-8 from the start of the string each time it is called, the second snippet runs in polynomial time, where the snippet that calls substr in a loop is linear.
With a few kilobytes of input, this makes mb_substr unacceptably slow.
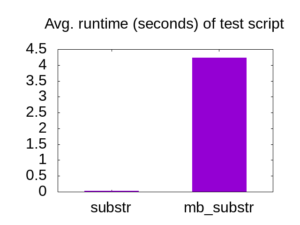
Averaging over 10 runs, the mb_substr snippet takes 4.23 seconds, while the snippet using substr takes 0.03 seconds.
What people should do
Split your strings into bytes or characters before you iterate, and write methods which operate on arrays rather than strings.
You can use str_split to iterate over bytes:
<?php
// Make a test string
$testString = str_repeat('a', 60000);
// Loop through test string
$testArray = str_split($testString);
$len = count($testArray);
for($i = 0; $i < $len; $i++) {
$c = $testArray[$i];
// Do work on $c
// ...
}
And for unicode strings, use preg_split. I learned about this trick from StackOverflow, but it might not be the fastest way. Please leave a comment if you have an alternative!
<?php
// Make a test string
$testString = str_repeat('a', 60000);
// Loop through test string
$testArray = preg_split('//u', $testString, -1, PREG_SPLIT_NO_EMPTY);
$len = count($testArray);
for($i = 0; $i < $len; $i++) {
$c = $testArray[$i];
// Do work on $c
// ...
}
By converting the string to an array, you can pay the penalty of decoding the UTF-8 up-front. This is a few milliseconds at the start of the script, rather than a few milliseconds each time you need to read a character.
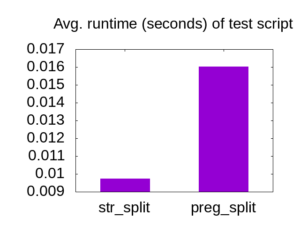
After discovering this faster alternative to mb_substr, I systematically removed every mb_substr and mb_strlen from the code I was working on.
Lesson 5: Optimize for the most common case
Around 50% of the remaining runtime was spent in a method which expanded templates.
To parse wikitext, you first need to expand templates, which involves detecting tags like {{ template-name | foo=bar }} and <noinclude></noinclude>.
My 40 kilobyte test file had fewer than 100 instances of { and <, | and =, so I added a short-circuit to the code to skip most of the processing, for most of the characters.
<?php
self::$preprocessorChars = [
'<' => true,
'=' => true,
'|' => true,
'{' => true
];
// ...
for ($i = 0; $i < $len; $i++) {
$c = $textChars[$i];
if (!isset(self::$preprocessorChars[$c])) {
/* Fast exit for characters that do not start a tag. */
$parsed .= $c;
continue;
}
// ... Slower processing
}
The slower processing is now avoided 99.75% of the time.
Checking for the presence of a key in a map is very fast. To illustrate, here are two examples which each branch on { and <, | and =.
This one uses a map to check each character:
<?php
// Make a test string
$testString = str_repeat('a', 600000);
$chars = [
'<' => true,
'=' => true,
'|' => true,
'{' => true
];
// Loop through test string
$testArray = preg_split('//u', $testString, -1, PREG_SPLIT_NO_EMPTY);
$len = count($testArray);
$parsed = "";
for($i = 0; $i < $len; $i++) {
$c = $testArray[$i];
if(!isset($chars[$c])) {
$parsed .= $c;
continue;
}
// Never executed
}
While one uses no map, and has four !== checks instead:
<?php
// Make a test string
$testString = str_repeat('a', 600000);
// Loop through test string
$testArray = preg_split('//u', $testString, -1, PREG_SPLIT_NO_EMPTY);
$len = count($testArray);
$parsed = "";
for($i = 0; $i < $len; $i++) {
$c = $testArray[$i];
if($c !== "<" && $c !== "=" && $c !== "|" && $c !== "{") {
$parsed .= $c;
continue;
}
// Never executed
}
Even though the run time of each script includes the generation of a 600kB test string, the difference is still visible:
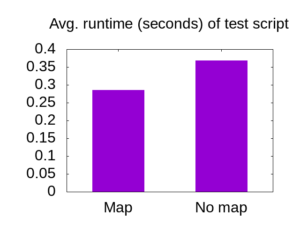
Averaging over 10 runs, the code took 0.29 seconds when using a map, while it took 0.37 seconds to run the example with used four !== statements.
I was a little surprised by this result, but I’ll let the data speak for itself rather than try to explain why this is the case.
Lesson 6: Share data between functions
The next item to appear in the profiler was the copious use of array_slice.
My code uses recursive descent, and was constantly slicing up the input to pass around information. The array slicing had replaced earlier string slicing, which was even slower.
I refactored the code to pass around the entire string with indices rather than actually cutting it up.
As a contrived example, these scripts each use a (very unnecessary) recursive-descent parser to take words from the dictionary and transform them like this:
example --> (example!)
The first example slices up the input array at each recursion step:
<?php
function handleWord(string $word) {
return "($word!)\n";
}
/**
* Parse a word up to the next newline.
*/
function parseWord(array $textChars) {
$parsed = "";
$len = count($textChars);
for($i = 0; $i < $len; $i++) {
$c = $textChars[$i];
if($c === "\n") {
// Word is finished because we hit a newline
$start = $i + 1; // Past the newline
$remainderChars = array_slice($textChars, $start , $len - $start);
return array('parsed' => handleWord($parsed), 'remainderChars' => $remainderChars);
}
$parsed .= $c;
}
// Word is finished because we hit the end of the input
return array('parsed' => handleWord($parsed), 'remainderChars' => []);
}
/**
* Accept newline-delimited dictionary
*/
function parseDictionary(array $textChars) {
$parsed = "";
$len = count($textChars);
for($i = 0; $i < $len; $i++) {
$c = $textChars[$i];
if($c === "\n") {
// Not a word...
continue;
}
// This is part of a word
$start = $i;
$remainderChars = array_slice($textChars, $start, $len - $start);
$result = parseWord($remainderChars);
$textChars = $result['remainderChars'];
$len = count($textChars);
$i = -1;
$parsed .= $result['parsed'];
}
return array('parsed' => $parsed, 'remainderChars' => []);
}
// Load file, split into characters, parse, print result
$testString = file_get_contents("words");
$testArray = preg_split('//u', $testString, -1, PREG_SPLIT_NO_EMPTY);
$ret = parseDictionary($testArray);
file_put_contents("words2", $ret['parsed']);
While the second one always takes an index into the input array:
<?php
function handleWord(string $word) {
return "($word!)\n";
}
/**
* Parse a word up to the next newline.
*/
function parseWord(array $textChars, int $idxFrom = 0) {
$parsed = "";
$len = count($textChars);
for($i = $idxFrom; $i < $len; $i++) {
$c = $textChars[$i];
if($c === "\n") {
// Word is finished because we hit a newline
$start = $i + 1; // Past the newline
return array('parsed' => handleWord($parsed), 'remainderIdx' => $start);
}
$parsed .= $c;
}
// Word is finished because we hit the end of the input
return array('parsed' => handleWord($parsed), $i);
}
/**
* Accept newline-delimited dictionary
*/
function parseDictionary(array $textChars, int $idxFrom = 0) {
$parsed = "";
$len = count($textChars);
for($i = $idxFrom; $i < $len; $i++) {
$c = $textChars[$i];
if($c === "\n") {
// Not a word...
continue;
}
// This is part of a word
$start = $i;
$result = parseWord($textChars, $start);
$i = $result['remainderIdx'] - 1;
$parsed .= $result['parsed'];
}
return array('parsed' => $parsed, 'remainderChars' => []);
}
// Load file, split into characters, parse, print result
$testString = file_get_contents("words");
$testArray = preg_split('//u', $testString, -1, PREG_SPLIT_NO_EMPTY);
$ret = parseDictionary($testArray);
file_put_contents("words2", $ret['parsed']);
The run-time difference between these examples is again very pronounced:
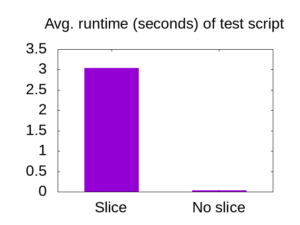
Averaging over 10 runs, the code snippet which extracts sub-arrays took 3.04 seconds, while the code that passes around the entire array ran in 0.0302 seconds.
It’s amazing that such an obvious inefficiency in my code had been hiding behind larger problems before.
Lesson 7: Use scalar type hinting
Scalar type hinting looks like this:
function foo(int bar, string $baz) {
...
}
This is the secret PHP performance feature that they don’t tell you about. It does not actually change the speed of your code, but does ensure that it can’t be run on the slower PHP releases before 7.0.
PHP 7.0 was released in 2015, and it’s been established that it is twice as fast as PHP 5.6 in many cases.
I think it’s reasonable to have a dependency on a supported version of your platform, and performance improvements like this are a good reason to update your minimum supported version of PHP.
By breaking compatibility with scalar type hints, you ensure that your software does not appear to “work” in a degraded state.
Simplifying the compatibility landscape will also make performance a more tractable problem.
Lesson 8: Ignore advice that isn’t backed up by (relevant) data
While I was updating this code, I found a lot of out-dated claims about PHP performance, which did not hold true for the versions that I support.
To call out a few myths that still seem to be alive:
- Style of quotes impacts performance.
- Use of by-val is slower than by-ref for variable passing.
- String concatenation is bad for performance.
I attempted to implement each of these, and wasted a lot of time. Thankfully, I was measuring the run-time and using version control, so it was easy for me to identify and discard changes which had a negligible or negative performance impact.
If somebody makes a claim about something being fast or slow in PHP, best assume that it doesn’t apply to you, unless you see some example code with timings on a recent PHP version.
Conclusion
If you’ve read this far, then I hope you’ve seen that modern PHP is not an intrinsically slow language. A significant speed-up is probably achievable on any real-world code-base with such endemic performance issues.
To repeat the graphic from the introduction: the test file could be parsed in 20.65 seconds on the old code, and 0.145 seconds on the improved code (averaging over 10 runs, as before).
At this point I declared my efforts “good enough” and moved on. The job is done: although another pass could speed it up further, this code is no longer slow enough to justify the effort.
Since I’ve closed the book on PHP 5, I would be interested in knowing whether there is a faster way to parse UTF-8 with the new IntlChar functions, but I’ll have to save that for the next project.
Now that you’ve seen some very inefficient ways to write PHP, I also hope that you will be able to avoid introducing similar problems in your own projects!